Abstract
Vision-language-action models (VLAs) have shown potential in leveraging pre-trained vision-language models and diverse robot demonstrations for learning generalizable sensorimotor control. While this paradigm effectively utilizes large-scale data from both robotic and non-robotic sources, current VLAs primarily focus on direct input-output mappings, lacking the intermediate reasoning steps crucial for complex manipulation tasks. As a result, existing VLAs lack temporal planning or reasoning capability. In this paper, we introduce a method that incorporates explicit visual chain-of-thought (CoT) reasoning into vision-language-action models (VLAs) by predicting future image frames auto-regressively as visual goals before generating a short action sequence to achieve these goals. We introduce CoT-VLA, a state-of-the-art 7B VLA that can understand and generate visual and action tokens. We demonstrates that CoT-VLA achieves strong performance in manipulation tasks in both the real world and simulation benchmarks.
Approach

We build our model on pre-trained VILA-U, a generative multi-modal model pre-trained on interleaved text--image data. The base model then trains on robot demonstrations and action-less videos. During deployment, given a visual observation and a text instruction, the model performs visual chain-of-thought reasoning by generating a subgoal image (upper blue) with causal attention. It then generates a short action sequences with full-attention for robot execution. The system operates in a closed-loop control manner by capturing new observations after executing predicted action sequences.
Experiments
Side-by-side visualization: Robot execution (green-bordered frames, left) with corresponding generated subgoal images (yellow-bordered frames, right) for each task.
Franka-Tabletop Benchmark
Multi-Instruction Tasks
"cover white bowl with towel"
"move yellow corn onto plate"
"knock green dinosaur over"
Single-Instruction Tasks
"put carrot in bowl"
"flip pot upright"
"move yellow corn onto plate"
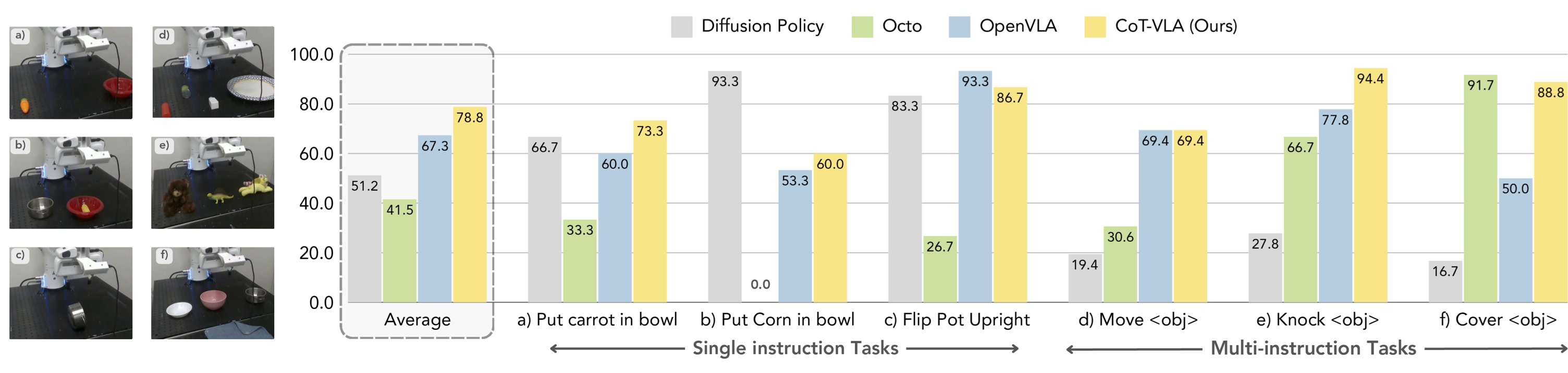
Franka-Tabletop experment comparison. Evaluation across six distinct manipulation tasks, with separate models trained per task. Left: Representative initial states for each task setup. Right: Task-specific success rates and cross-task averages for our method and baselines. CoT-VLA achieves best average performance and demonstrates strong capabilities in both single-instruction and multi-instruction scenarios.
LIBERO Benchmark

LIBERO benchmark comparison. For each task suite (Spatial, Object, Goal, Long), we report the average success rate and standard deviation across 3 trials over 500 testing initial states. Our method achieves the best or competitive performance across all LIBERO benchmarks suites compared to baseline approaches.
Bridge V2
"Put the eggplant in the pot" (visual)
"Put the carrot on the plate" (motion)
"Put the red bottle into the pot" (language)
"Take the purple grapes out of the pot" (semantic)
Ablation Studies
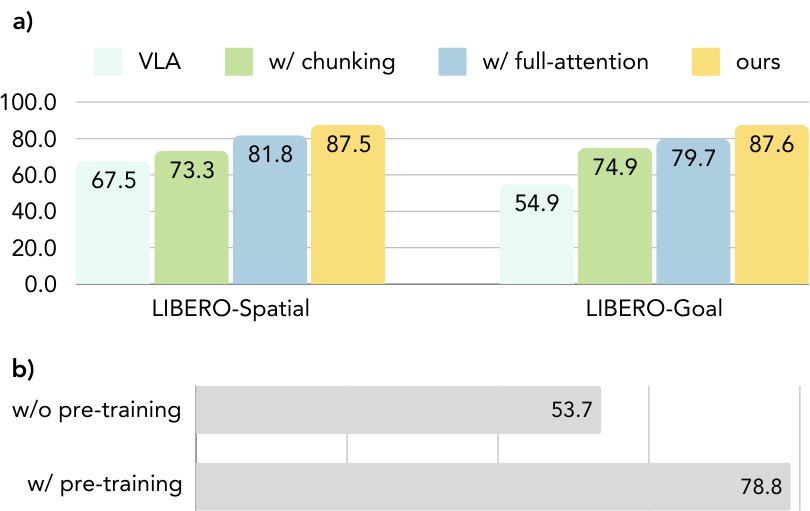
a) Results on LIBERO-Spatial and LIBERO-Goal benchmarks demonstrate the effectiveness of three components: action chunking (w/ chunking), full-attention action decoding (w/ full-attention), and visual chain-of-thought reasoning (ours).
b) Pre-training ablation experiments on Franka-Tabletop show performance improvements from the first-stage pre-training process.